When a peer-reviewed paper reports that two emissions inventories disagree by 70% across 260 US cities, and the dataset producer replies that the current gap is closer to 6%, the question is not which number is correct. The question is how anyone is supposed to know.
That is the dispute now unfolding between Climate TRACE - the AI-driven global emissions inventory backed by Al Gore - and Kevin Gurney’s group at Northern Arizona University, who run the Vulcan Project, the most spatially detailed government-data inventory of US emissions. The coverage focused on the 70%. The structure underneath the dispute matters more.
The dispute, briefly
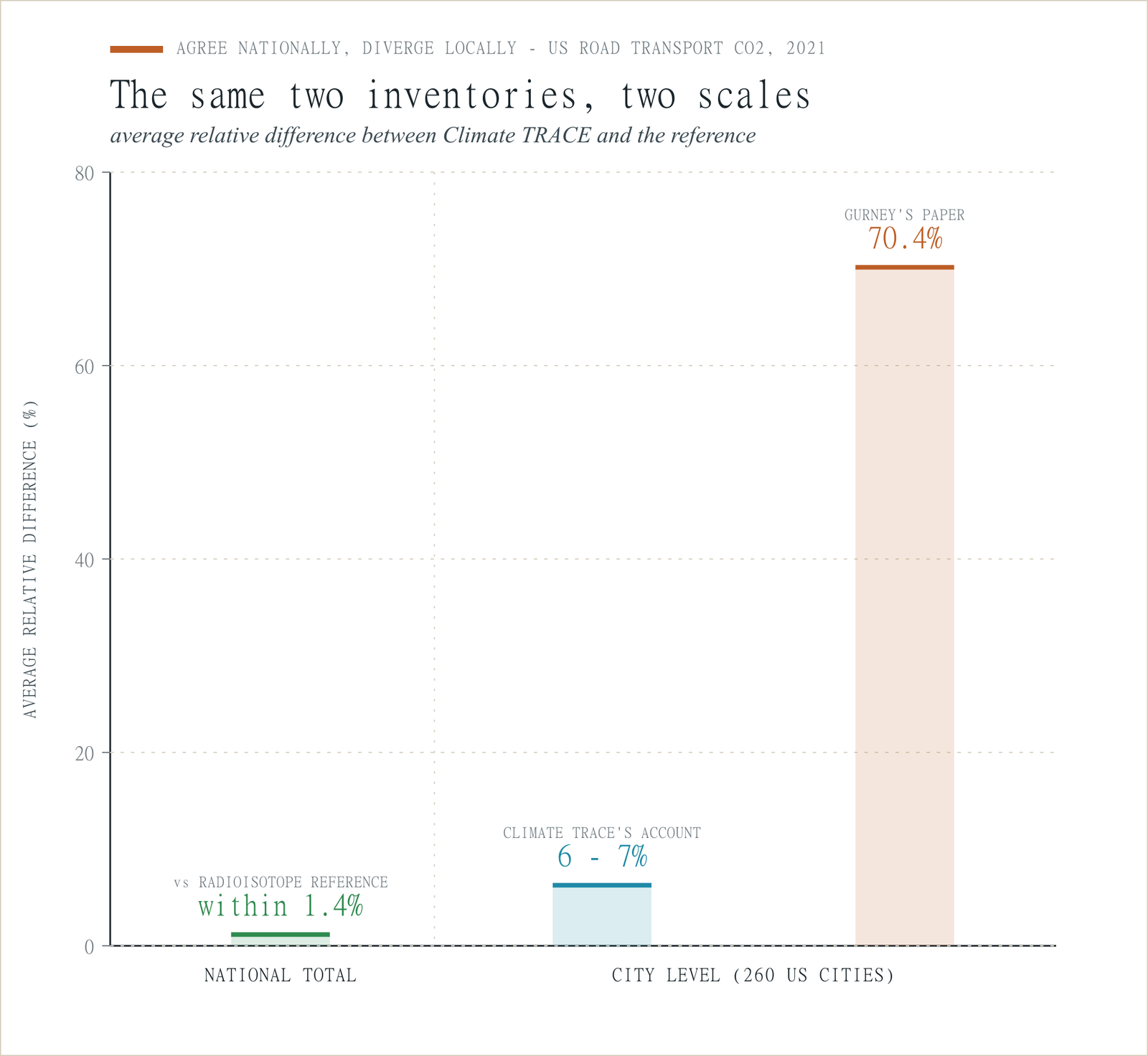
The Gurney paper, published in Environmental Research Letters on 5 May 2026, compared Climate TRACE’s urban vehicle CO2 emissions against Vulcan across 260 US cities for 2021 and reported an average relative difference of -70.4%, with Indianapolis and Nashville more than 90% lower than Vulcan. It identified suspected causes - ML model bias, fuel economy assumptions, fleet distribution values - and urged caution from policymakers.
Climate TRACE’s response, published three days later, disputed the framing. It said the paper relied on a two-month cities-aggregation bug in data version 4.1.0 - identified in March 2025, fixed in May 2025, documented in a public changelog. Climate TRACE reports current city-level gaps with Vulcan averaging 6-7%, with county and national totals within 1.4%. By its account, the headline 70% describes a known and patched bug, not the current dataset.
Both accounts can be technically defensible. Both cannot describe the dataset a policymaker would download today. The gap between them is the structural problem worth examining.
The aggregate paradox
Even in Climate TRACE’s preferred framing, where the city-level gap is 6-7%, both inventories pass the same national-level accuracy test.
Climate TRACE reports its 2021 US road transport total as 1.5 billion tonnes CO2 equivalent. The official US inventory submitted to the UNFCCC was 1.45 billion tonnes. Both Climate TRACE and Vulcan report national totals within 1.4% of an independent radioisotope-based atmospheric measurement, which infers CO2 origin by tracing carbon isotope ratios. Two inventories, two methodologies, two completely independent input chains - converging on a national number well within their stated uncertainties.
Yet they disagree at the city level by 6-7% on average by Climate TRACE’s account, and by 70% on average by Gurney’s. Either way, the spatial disagreement is much larger than the national one.
That is not a dataset disagreement. It is a measurement resolution problem.
Aggregate validation is not spatial validation. A national total can be correct even if every city-level estimate is wrong, as long as the errors cancel across the country. The radioisotope check sees the total carbon flux. It does not see where inside the 260 cities the emissions are coming from.
Policymakers do not make decisions at national scale. A city transport authority, a regional planning body, a compliance officer writing a net-zero transition plan - they need the city-level number. Whether that number is wrong by 70%, by 7%, or by some other amount depending on the version they pulled, the user has no way to know.
Two methodologies, one missing layer
Climate TRACE does not count cars. It infers activity. The road transport methodology, developed with Johns Hopkins Applied Physics Laboratory, uses satellite imagery to estimate traffic on road segments and applies machine-learned emissions factors per segment. Climate TRACE as a whole draws on more than 300 satellites and over 11,000 sensors; the road transport model uses a subset in combination with reference and ground data.
Vulcan uses government datasets as primary inputs: fuel consumption, vehicle registrations, road network topology, travel demand models. It places emissions where the fuel was actually burned. Its on-road uncertainty has been independently estimated at +/-14.2%.
Neither method is obviously wrong in principle. Climate TRACE’s response identifies a versioned bug as the cause of the 70% gap; the Gurney paper identifies model-layer hypotheses. Both lists are plausible. Neither addresses the layer below.
Satellite-derived model inputs from many sensors do not automatically share a common, uncertainty-traceable radiometric scale suitable for cross-sensor ML inference. Individual sensors are typically calibrated against their own internal references and distributed as radiance or reflectance products. But the practice of harmonising those products across the dozens or hundreds of sensors that contribute to a single ML training set - with documented, per-observation uncertainty that propagates through the model - is far less mature. When a system is built on satellite imagery plus ground reference data, the calibration state of those visual inputs becomes part of the model whether or not it is treated explicitly.
I have not found a public, observation-level description of how inter-sensor radiometric calibration uncertainty is propagated through Climate TRACE’s road transport ML pipeline. If one exists, I would welcome the correction. Without such a description, the user has no way to decompose the error - to separate ML model bias from calibration input inconsistency from atmospheric correction differences from activity model assumptions from a versioning bug. Every hypothesis about the model is confounded by uncertainty about the inputs.
This is not a problem unique to Climate TRACE. It is a structural property of satellite-derived data products built on inputs whose calibration provenance is not exposed in a standardised, observation-level form.
What attributable error would change
Calibration does not fix an ML model. It does not correct a wrong fuel economy assumption. It does not fix a cities-aggregation bug. What it does is make the error attributable.
If the satellite inputs to a road transport ML pipeline carried documented, propagatable calibration uncertainty, it would be possible to hold the model fixed, vary the calibration state of the inputs, and see how much of the spatial discrepancy moves. If a large fraction moves, the dominant source is upstream of the model. If little moves, the problem is elsewhere.
Layered on top of that: versioned provenance. Every published comparison should be reproducible against the specific version of the dataset it evaluated. A reader looking at Gurney’s paper today should be able to identify the data version it used, the changelog entries that have since been applied, and the magnitude of change those entries produced at the spatial scales the paper analysed. Climate TRACE publishes monthly releases and a public changelog. That is genuinely useful - and not yet sufficient to let a downstream user bound the difference between “the version this paper evaluated” and “the version I am about to make a policy decision with” with a quantified, propagatable confidence interval.
This matters because the Climate TRACE dispute will not be the last one. Carbon markets, CBAM compliance, corporate Scope 3 reporting, city-level climate transition plans - all of these are being built on EO-derived data products, often by users who do not have the time or the standing to investigate which version of which inventory their conclusions depend on.
Legible uncertainty
Gurney’s conclusion is that Climate TRACE’s on-road CO2 estimates should be “used with caution.” Climate TRACE’s conclusion is that the 70% rests on outdated data and current differences are normal. Both can be true at once. Neither tells a policymaker what uncertainty to attach to the number they are actually using.
A measurement that says “1.2 million tonnes CO2, +/-14%, version 5.6.0” is more useful than one that says “1.8 million tonnes CO2, uncertainty unknown” - even if the first number is further from truth. The policymaker knows what they are working with, can decide how much to discount it, and can reproduce a published finding against the version of the data they are about to use.
Gurney’s previous work on Climate TRACE’s power plant CO2 found a similar pattern - significant source-level differences against an independent reference, even where national totals agreed. Together, power plants and vehicles account for more than half of US fossil fuel CO2 emissions in cities. The pattern is not a bug in any one methodology that can be patched. It is a signal about what happens when inference products are built on inputs and version histories that carry no certified, downstream-usable uncertainty.
Where this leaves the calibration question
Climate TRACE set out to do something genuinely hard: produce a global, independent, near-real-time inventory of greenhouse gas emissions, without waiting for governments to self-report. The dispute with Gurney is a feature of a maturing field, not a scandal. Both parties are doing serious work.
What is missing is the infrastructure that would let the rest of the world use the work safely. Three pieces of that infrastructure are visibly absent in this dispute: spatial validation against an independent reference at the scale the data product claims to support; versioned provenance that lets a downstream user reproduce any published finding against the data they currently hold; and propagatable input uncertainty that lets model error be decomposed and attributed.
The dispute between Gurney and Climate TRACE will continue. The methodology will improve. Some of the gap will close. What will not change, without that underlying infrastructure, is the structural ambiguity that gives a peer-reviewed paper one number and a dataset producer’s response a different number, an order of magnitude apart, with no shared chain of custody for the difference.
That chain of custody is what the next generation of EO products has to build.
Kevin R. Gurney et al., “Assessing the accuracy of the Climate Trace global vehicular CO2 emissions,” Environmental Research Letters 21 (2026) 094018, DOI: 10.1088/1748-9326/ae6355. Climate TRACE response: “Climate TRACE Road Transportation Emissions: Correcting the Record on City-Level Accuracy,” climatetrace.org, 8 May 2026. https://climatetrace.org/news/climate-trace-nau-road-transport-emissions